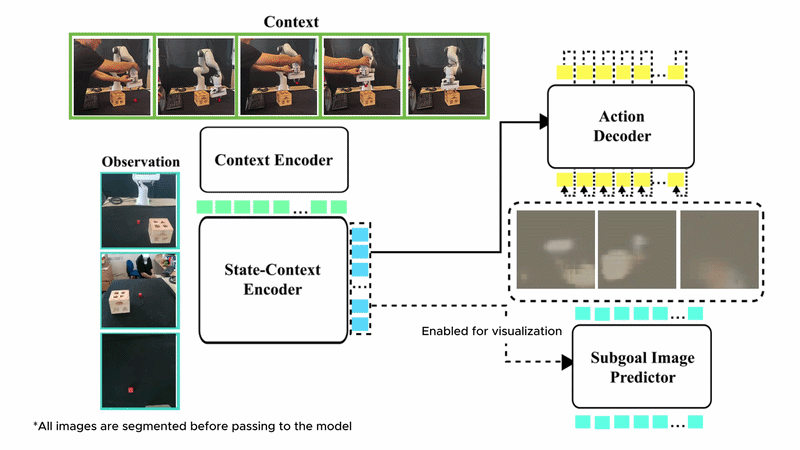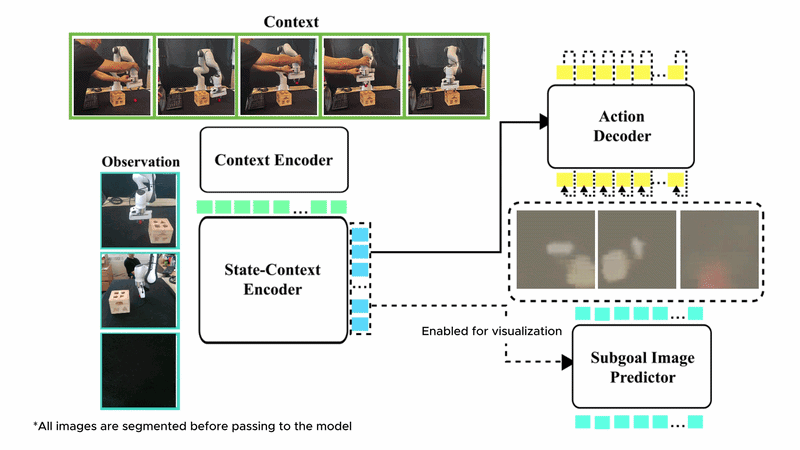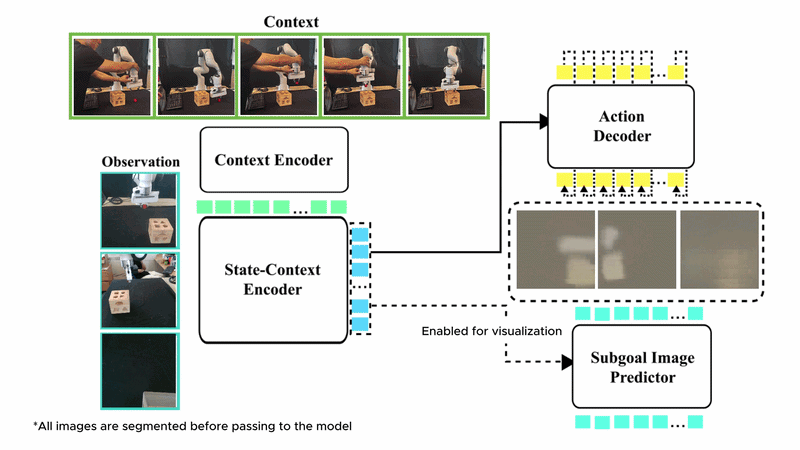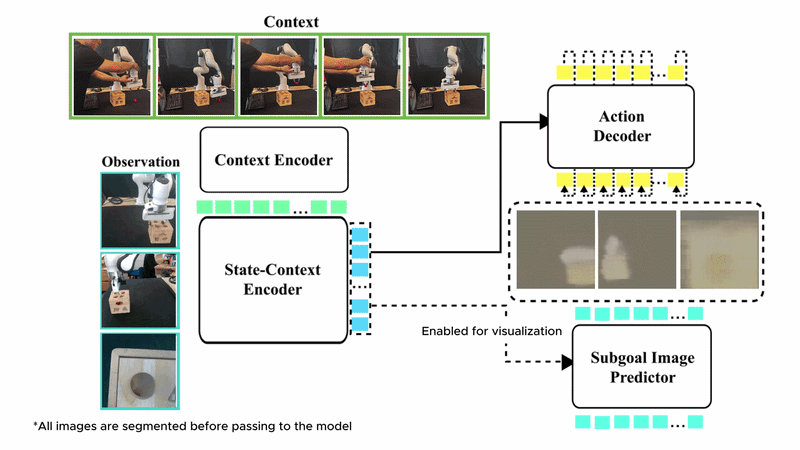
In-context imitation learning (ICIL) enables robots to learn new tasks from a small number of demonstrations by conditioning a pre-trained policy on task-specific examples, without retraining at test time. Despite this promise, training generalizable and scalable in-context imitation policies remains an open challenge.
We present SynthICL, a scalable framework that trains ICIL policies entirely from RGB-only synthetic data. Specifically, we build a data generation pipeline to produce high-fidelity ICIL data and train a flow-matching transformer policy on the resulting dataset. SynthICL avoids the need for depth sensing, precise camera calibration, and real-world training data in prior approaches, offering a simpler and more scalable alternative.
We further incorporate subgoal prediction by training the model to predict the next subgoal images, enabling more precise and visually grounded control. Evaluated on 16 unseen real-world manipulation tasks, SynthICL achieves an average success rate of 79% with only one demonstration provided at test time and outperforms prior methods.